Tesseract.js is a javascript port of the famous Tesseract OCR engine and it is an optical character recognition engine for various operating systems. It is a free software, released under the Apache License and development has been sponsored by Google since 2006.
What is OCR?
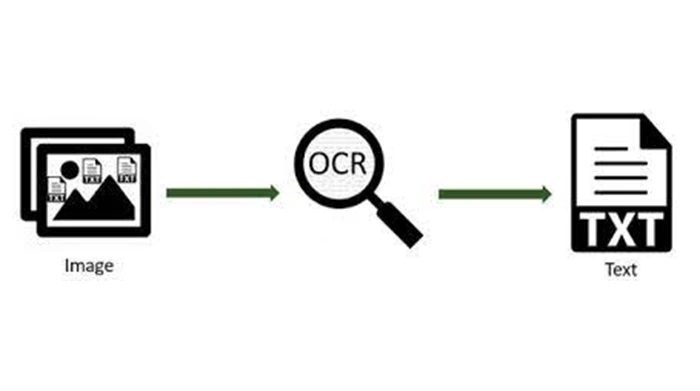
Optical Character Recognition or Optical Character Reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten, or printed text into machine-encoded text, whether from a scanned document, a photo of a document or a scene-photo. To better understand how OCR works, look at the diagram process in the following picture. From end-user’s side, the OCR process is very simple - just processing the image and get the editable text.
How to use Tessearct.js in Mendix
Prerequisites:
Community commons
Implementation:
In this blog, I’ll show you how to use Tesseract.js to build an OCR in the Mendix application.
1) Use ‘SUB_GetBase64Image’ to convert image to base64 where base64 java action is used and pass it to ‘JS_ImageOCR javascript’ action
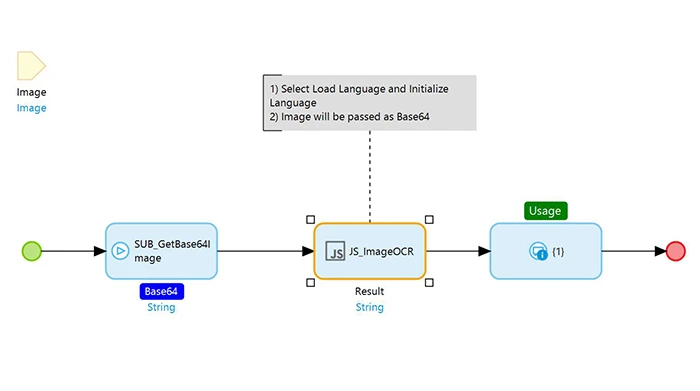
2) Select Load Language and Initialize Language
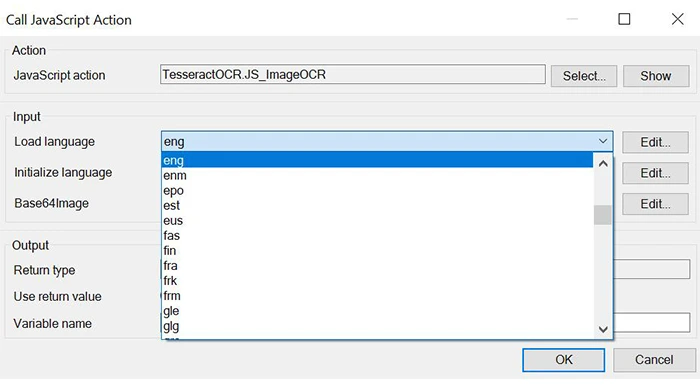
3) Result - Fetch text from an image as string type
Code Explanation
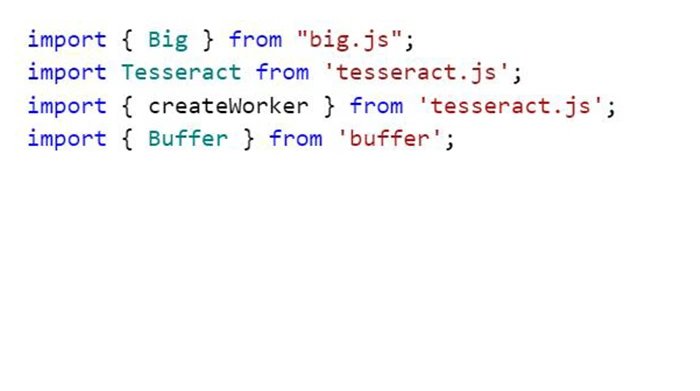
1) Import tesseract.js and buffer
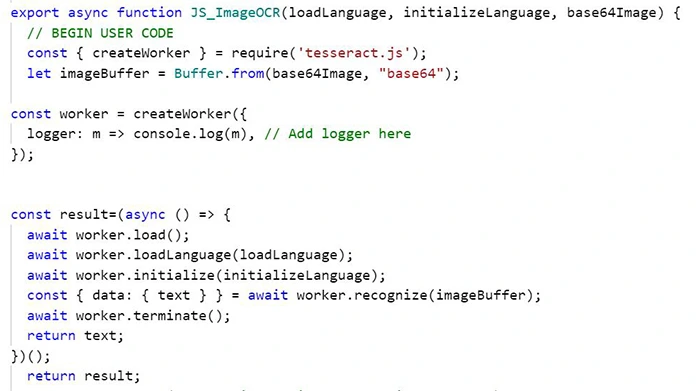
2) Initialize And Run Tesseract
A Worker helps you to do the OCR-related tasks, it takes a few steps to setup Worker before it is fully functional. The full flow is as follows:
• FS functions // optional
• loadLanguauge
• initialize
• setParameters // optional
• recognize or detect
• terminate
Each function is async, so using async/await or Promise is required. When it is resolved, you get a TesseractJob object.
a) Worker.loadLanguage(langs):
Worker.loadLanguage() loads traineddata from cache or download traineddata from remote and put traineddata into the WebAssembly file system.
Arguments:
langs a string to indicate the languages traineddata to download, multiple languages are concated with +, ex: eng+chi_tra
b) Worker.initialize(langs):
Worker.initialize() initializes the Tesseract API, and make sure it is ready for doing OCR tasks.
Arguments:
langs a string to indicate the languages loaded by Tesseract API, it can be the subset of the language traineddata you loaded from Worker.loadLanguage.
c) Worker.recognize(image):
Worker.recognize() provides the core function of Tesseract.js as it executes OCR
Figures out what words are in the image, where the words are in the image, etc.
Note: Image should be in sufficient high resolution. Often, the same image will get much better results if you upscale it before calling recognize.
Arguments:
image see Image Format for more details.
Examples:
https://github.com/naptha/tesseract.js/blob/master/docs/examples.md
Supported File
This is the supported type from Tesseract that could be read by their engine:
1. JPG
2. PNG
3. PNM
4. TIFF
Features:
• It supports multiple languages, check here for a complete list of supported languages.
• The accuracy is high with normal fonts and clear background
Limitations:
• Accuracy will be low with noisy backgrounds and custom-scripted fonts.
• Tesseract doesn’t support all file formats by itself
• The image quality must reach a certain threshold of Dots per Inch (DPI) points for it to work
Conclusion:
After having fun working with Tesseract OCR, I can say that the engine is amazing! It brings the power of OCR to the browser and opens a door of opportunities for developers. Here a list of interesting point from Tesseract in my opinion:
1. Open Source.
2. Easy to use.
3. Good extract result.
4. Support multi-language.
If you are facing some issues and think OCR is your solution, Tesseract would be nice to try! I hope this article is useful for you. Thank you!!