Voice cloning AI model enables the user to create an artificial simulation of a person's voice.
The process of voice cloning involves recording a person's voice for several hours, which is then used to create a digital model of their speech patterns. This model is then fed into a text-to-speech engine that can convert text into speech which sounds like the original speaker's voice. The technology uses deep learning algorithms to analyze the audio data and extract the nuances of the speaker's voice, including tone, pitch, and pronunciation.
Yes, the future is here!! In this age of technological evolution, this revolutionary speech synthesis would sure make heads turn! This Eleven Labs AI Speech Software presents an incredible product which allows the user to train any 60 seconds of a person’s voice note. This can be synthesized with the text samples which we enter.
Now, we shall see how this Voice Cloning functionality is developed in the Mendix Platform.
Implementation on Mendix
The level of accuracy to which the Voice Cloning technology can convert a person’s voice is truly remarkable. This awe-inspiring technology has been integrated with Mendix using Eleven Labs APIs.
What do we need?
- Play Audio - https://marketplace.mendix.com/link/component/120804
- API Key – From Eleven Lab Profile section
Getting Started
On Eleven Labs, go to the Profile section where you can able to find the API key
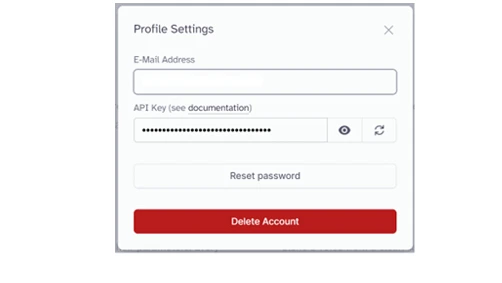
The above screenshot explains how we can get the API Key which needs to be used in the Mendix Modeler.
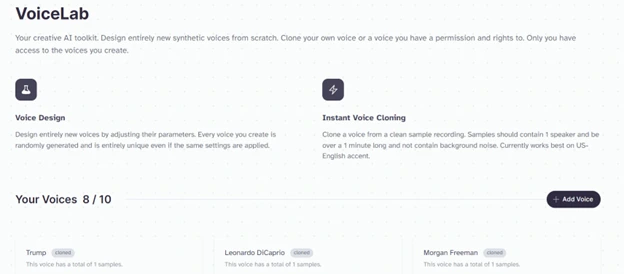
From the Voice Lab page we could train or synthesize the voice that we want.
Example:
I have cloned about 8 voices here. Each voice contains about 60 sec of the corresponding audio clip.
On the Mendix perspective, we can GET all those voices using REST API’s. Add the data view into the page and call the below microflow in the data source.
To GET all the voices which have been cloned in a customizable manner, perform the REST activity configure as below:
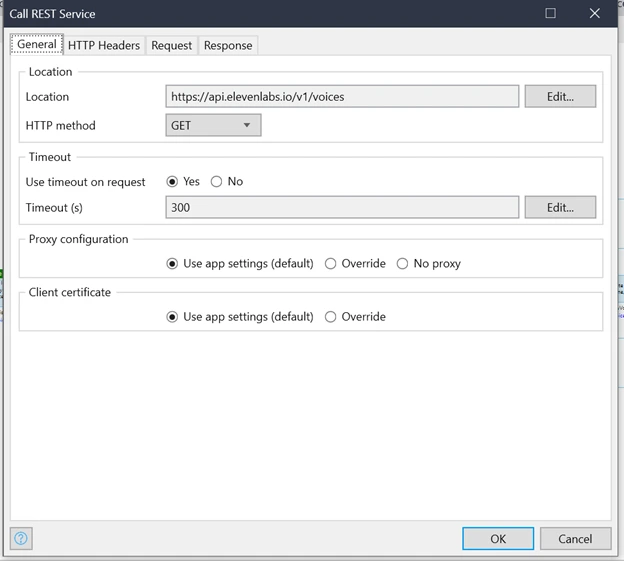
Call GET HTTP Method with the mentioned URL.
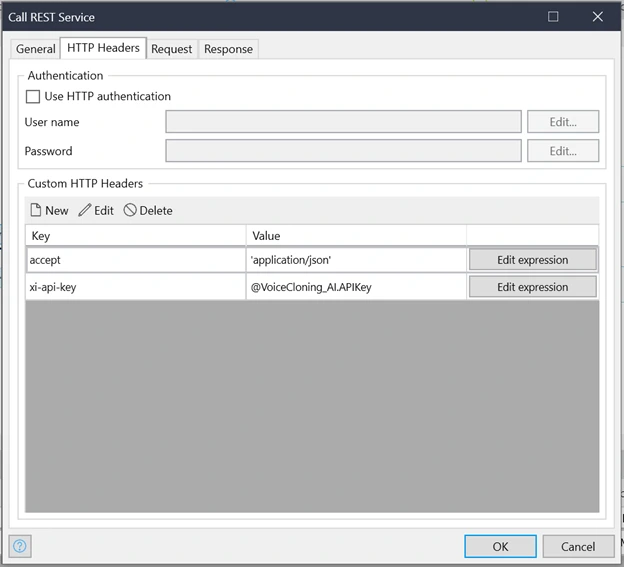
HTTP Headers
As the next step, we must create the Import mapping and JSON structure to get the Response.
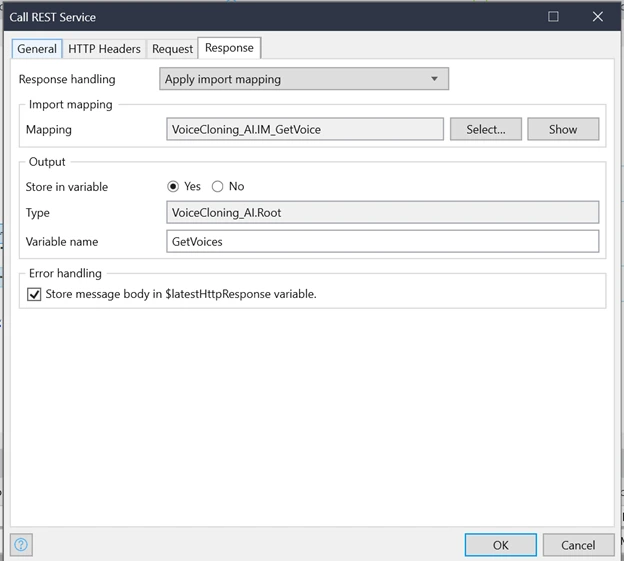
Response Handling
JSON Structure

Once everything gets executed, we will be able to get all the voices which have been configured inside the Overview Page as shown below:
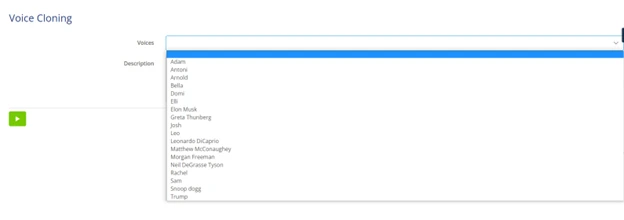
Here, we can find some sample voices that are already present in the Eleven Labs. As seen in the above screenshot, we have added some of the cloned voices which would be easy to identify. With the help of Play Audio Widget, we have incorporated logic in the nanoflow using JS Snippet to play the cloned voice.
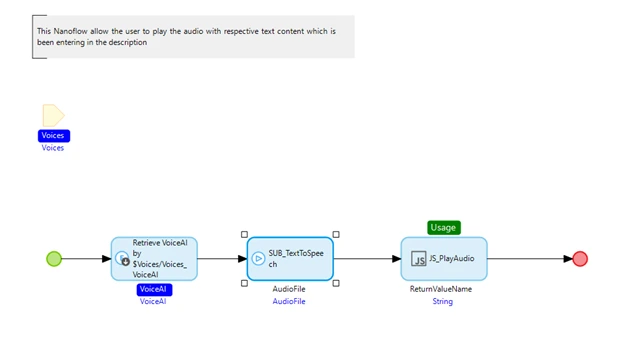
Inside the nanoflow, a microflow has been added to use the POST REST Service to generate and stream the cloned voice with the respective texts.
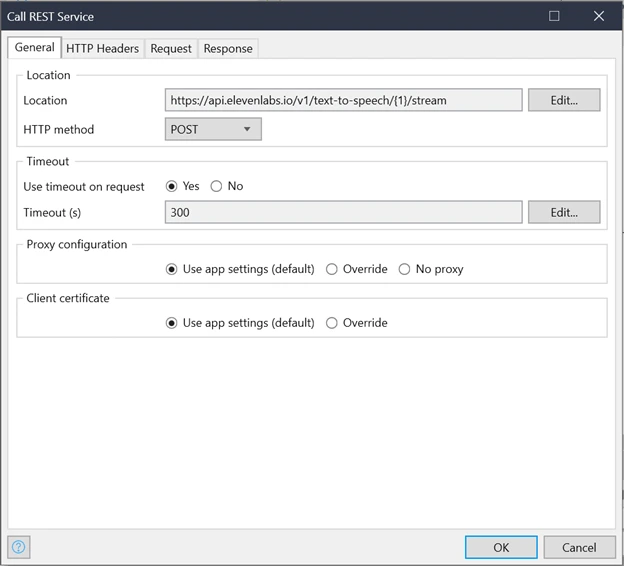
POST Method and the End Point URL to stream the audio.
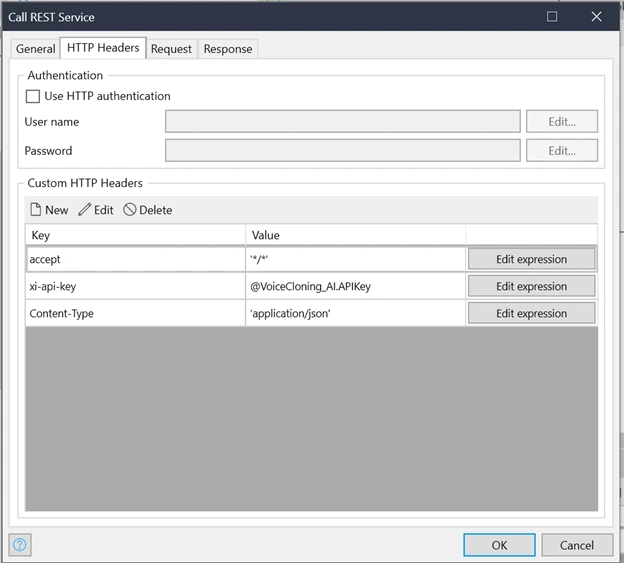
HTTP Headers

Pass the Request Body
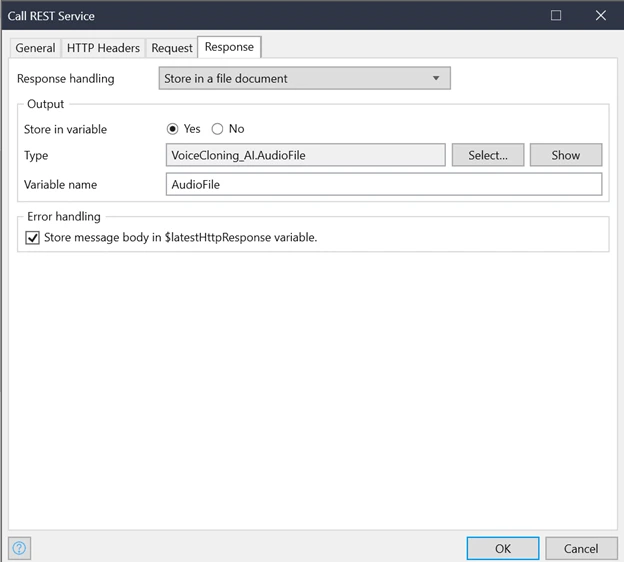
Make the response to store it in a file document.
Once all set, return the object in the Play Audio activity which has been used in the Nanoflow to stream the expected output.
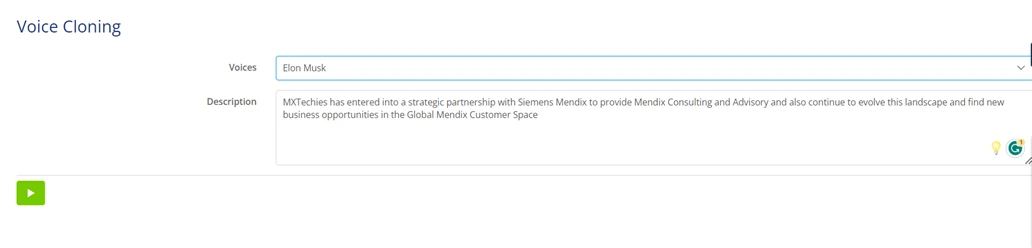
Finally, the cloned voice will look like this.
For API Reference - https://api.elevenlabs.io/docs