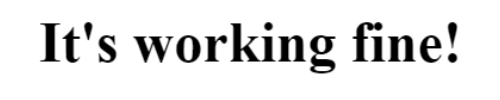Overview
The Tesseract OCR is used to extract text from image using tesseract.js library which is an open source library. It supports multiple languages with higher accuracy.
Documentation

The Tesseract OCR is used to extract text from image using tesseract.js library which is an open source library.
It supports multiple languages with higher accuracy.
Prequisites :
Community commons
Implementation:
-
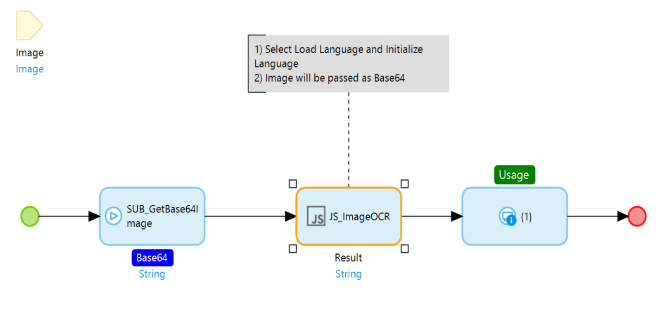
Use 'SUB_GetBase64Image' to convert image to base64 where base64 java action is used.
-
Select Load Language and Initialize Language in 'JS_TesseractOCR' javascript action
Result :
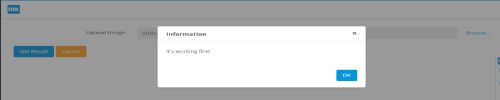
Fetch text from image as string type
Supported File:
-
JPG
-
PNG
-
GIF
-
PNM
-
TIFF
Features :
-
It supports multiple languages. Please check HERE for supported languages.
-
The accuracy is pretty high with normal fonts and clear background
Limitation:
Accuracy will be low with noisy backgrounds and custom scripted fonts.