Overview

Utilized for modifying, parsing, or examining strings (sequences of characters) in processes like data cleaning, text processing, and producing formatted output.
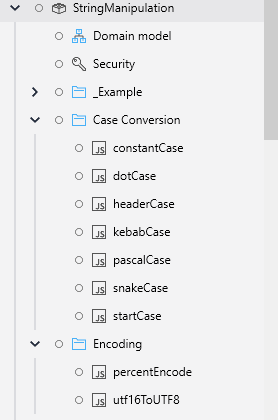
Features
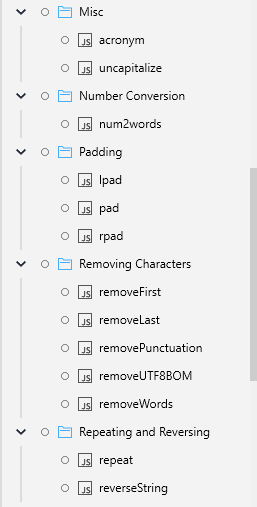
Padding :
-
lpad - left pad a string
-
rpad - right pad a string
-
pad - pad a string
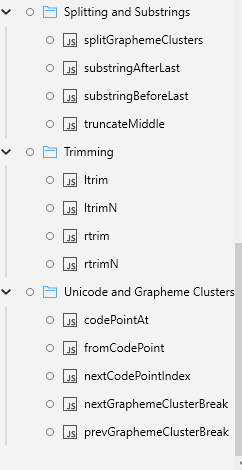
Trimming :
-
ltrim - trim whitespace characters from the beginning of a string
-
rtrim - trim whitespace characters from the end of a string
-
ltrimN - trim n characters from the end of a string
-
rtrimN - trim n characters from the end of a string
Case Conversion :
-
constantCase - convert a string to constant case
-
dotCase - convert a string to dot case
-
headerCase - convert a string to HTTP header case
-
kebabCase - convert a string to kebab case
-
pascalCase - convert a string to Pascal case
-
snakeCase - convert a string to snake case
-
startCase - capitalize the first letter of each word in a string
Removing Characters :
-
removeFirst - remove the first character(s) of a string
-
removeLast - remove the last character(s) of a string
-
removePunctuation - remove punctuation characters from a string
-
removeUTF8BOM - remove a UTF-8 byte order mark (BOM) from the beginning of a string
-
removeWords - remove a list of words from a string
Splitting and Substrings :
-
splitGraphemeClusters - split a string by its grapheme cluster breaks
-
substringAfterLast - return the part of a string after the last occurrence of a specified substring
-
substringBeforeLast - return the part of a string before the last occurrence of a specified substring
-
truncateMiddle - truncate a string in the middle to a specified length
Repeating and Reversing :
-
repeat - repeat a string a specified number of times and return the concatenated result
-
reverseString - reverse a string
Encoding :
-
percentEncode - percent-encode a UTF-16 encoded string according to RFC 3986
-
utf16ToUTF8 - convert a UTF-16 encoded string to an array of integers using UTF-8 encoding
Unicode and Grapheme Clusters :
-
codePointAt - return a Unicode code point from a string at a specified position
-
fromCodePoint - create a string from a sequence of Unicode code points
-
nextCodePointIndex - return the position of the next Unicode code point in a string after a specified position
-
nextGraphemeClusterBreak - return the next extended grapheme cluster break in a string after a specified position
-
prevGraphemeClusterBreak - return the previous extended grapheme cluster break in a string before a specified position
Number Conversion :
-
num2words - convert a number to a word representation
Misc :
-
Acronym - generate an acronym for a given string
-
uncapitalize - uncapitalize the first character of a string
Dependencies:
Mendix modeler 9.12.4.
Issues, suggestions and feature requests
https://github.com/bharathidas/String-Manipulation/issues
Screenshots :